

Data analysis and Machine Learning-پنج شنبه 14-8 *
کامپیوتر | دوره های برنامه نویسی | Data analysis and Machine Learning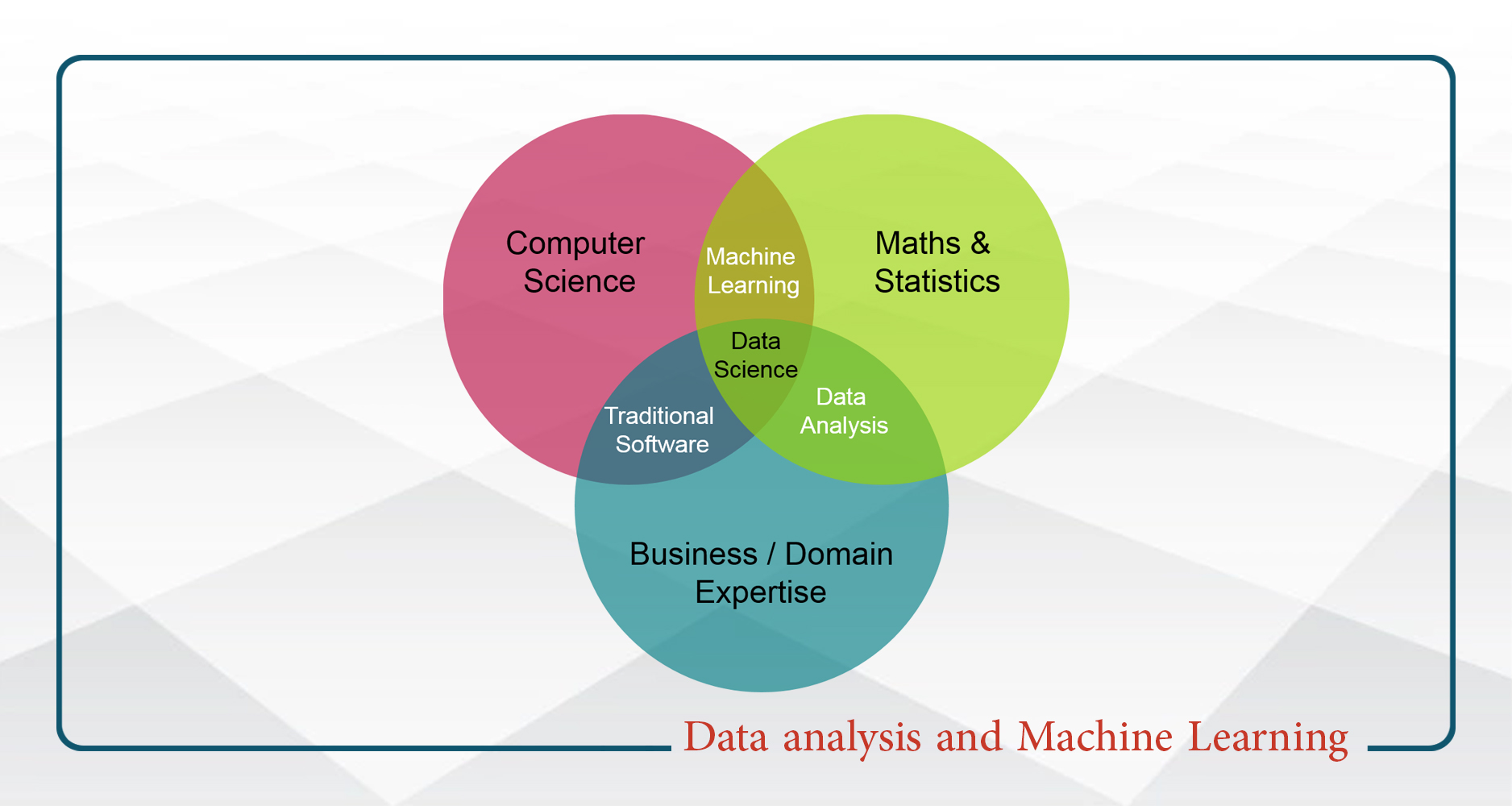
50 ساعت
8 جلسه
پنج شنبه
08:00 الی 14:00
فرصت باقیمانده ثبت نام:
فرصت ثبت نام به پایان رسیده
ظرفیت باقیمانده: 7تاریخ پایان: 1402/05/21
قیمت دوره: 4,000,000 تومان
Data analysis and Machine Learning (آنالیز داده و یادگیری ماشین)
عصر دیجیتال در حال توسعه و پیشروی است و در کنار خود دنیای هوشمندی را پدید آورده است که با زندگی انسان ها عجین شده است. کلیه فعالیت انسان ها به صورت جریان های داده ای در حال گذر از این دنیای هوشمند میباشد و امروزه شناسایی بهتر این دنیا و نحوه ی ارتباط آن با انسان ها به یکی از دغدغه های اصلی بشر تبدیل شده است. در این دوره ضمن آشنایی با مفهوم داده سعی بر آن خواهیم کرد که داده های مختلف در دنیای هوشمند را جمع آوری کنیم. با انجام عملیات مختلف تحلیل های اولیه از داده ها خواهیم داشت و در ادامه با ورود به دنیای آمار و مصور سازی داده ها سعی بر پرده برداری از این دنیای هوشمند و جریان داده ای موجود در آن خواهیم کرد. در بخش دوم از این دوره نوبت به طراحی و ساخت عامل های هوشمند می رسد. این عامل ها در کنار انسان همراه با هوشمندی قابل توجهی که دارند سعی خواهند کرد که به صورت کاراتر داده های اطراف ما را تحلیل کنند الگوهای گوناگون را استخراج کنند و اطلاعات خود را با ما در میان بگذارند. بهبود عملکرد آنان در کنار معرفی عامل های گوناگون ، از دیگر اهداف این دوره است.
پیش نیاز دوره:
- آشنایی با آمارو احتمال
- گذراندن دوره پایتون
اهداف برگزاري دوره:
- گذراندن این دوره پیش نیاز شاخه های گوناگون دانش هوش مصنوعی و برنامه نویسی هوشمند می باشد.
- گذراندن این دوره منجر به تحلیل و مدیرت داده های گوناگون در حوزه های مختلف بازار دیجیتال می شود.
تواناييهاي مورد انتظار از فراگيران در پايان دوره:
- تحلیل داده
- آشنایی با الگوریتم های یادگیری ماشین و به کارگیری آن ها
- کار با پکیج های مختلف آنالیز داده
زمينههاي اشتغال زايي دوره:
توجه به رشد روز افزون داده ها در دنیای دیجیتال ، امروزه تحلیل این داده ها و استخراج اطلاعات گوناگون از آنان جزو نیاز های اصلی این بازار به شمار می رود و این مورد باعث افزایش بازار کار افراد متخصص در این حوزه خواهد شد.
موضوع مدل های هوشمند و بررسی داده های مختلف در حوزه های گوناگون از فناوری های نوین عصر دیجیتال به شمار می آید از این رو با توجه به فقدان افراد متخصص در این حوزه ، بازار کار بکر و بزرگی در این بخش از عصر دیجیتال دیده می شود.
فصل اول: کتابخانهی numpy
- مقدمه - یادگیری ماشینی چیست؟
- آموزش پکیج numpy در numpy - array ها و ماتریسها
- broadcasting در numpy
- جمع، تفریق، تقسیم و جذر در numpy
- متدها و فیلتر کردن در numpy
- میانگین، واریانس، میانه، کواریانس و مقدار تعداد تکرار
فصل دوم: کتابخانهی pandas
- پکیج pandas
- دیتافریم (data frame) چیست؟
- متدهای دیتافریم
- مرتب کردن دادهها
فصل سوم: کتابخانهی matplotlib
- نمودار در matplotlib
- رسم نمودار
- آموزش رسم نمودار جزییات در نمودار رنگها
- رسم دو نمودار همزمان و اضافه کردن جزییات
- رسم چند نمودار در کنار هم
- پکیج seaborn
- پکیج boxplot
- jointplot ها و pairplot ها
فصل چهارم: مباحث آمار
- اهمیت آمار
- نمودار ECDF
- کمیتهای آماری
- کواریانس
- correlation
- (pearson)
- روشهای غیرپارامتریک correlation
- chi-square
- کاربرد chi-square
- تست chi-square با پایتون
- مفهوم احتمال
- توزیع نرمال
فصل پنجم: پیشپردازش دادهها
- preprocessing چیست؟
- preprocessing در پایتون
- دادههای خالی (nan)
- پر کردن دادههای خالی
- دادههای تکراری
- تبدیل دادههای غیرعددی به عددی
- Crosstab ها و pivot_table ها
- متغیرهای ساختگی (dummy variables)
- نرمال کردن دادهها
- نویز و داده پرت و تفاوت آنها
فصل ششم: یادگیری نظارت شده (Supervised Learning)
- یادگیری نظارتشده (Supervised Learning)
- وارد کردن دیتاست iris
- الگوریتم knn
- متریک در الگوریتم KNN
- چگونگی بررسی عملکرد یک الگوریتم
- overfitting و underfitting
- رگرسیون خطی چیست؟
- دیتاست boston و تمرین برای linear regression
- خطا در linear regression چگونه محاسبه میشود؟
- تقسیم کردن اطلاعات به چند بخش (K_fold cross validation)
- تابع جریمه, Regularization term ,ridge regression ,Lasso regression
- confusion matrix
- لجیستیک رگرسیون چیست؟
- threshold در Logistic regression
- روشی برای پیداکردن هایپر پارامترها
- تعیین هایپر پارامترها Random search cross validation
- Naive Bayes
- الگوریتم شبکه عصبی چیست؟
فصل هفتم: یادگیری نظارت نشده (Unsupervised Learning)
- یادگیری غیر نظارت شده ، clustering و k_means چیست؟
- نحوه کد زدن k_means و انتخاب تعداد cluster یا inertia
- خوشهبندی سلسله مراتبی یا Hierarchical Clustering
- الگوریتم Mean Shift
- الگوریتم DBSCAN
برای این کلاس نظری ثبت نشده است.